Convertendo linhas em colunas no SQL Server usando PIVOT
Aprenda a transformar linhas em colunas no SQL Server
Durante o trabalho de análise de dados, sempre se faz necessário converter os dados de modo a atender as necessidades de nossos usuários. Uma forma de conversão muito útil é fazer o agrupamento de dados exibidos em linha, para que cada elemento distinto da linha seja transformado numa coluna. Vamos fazer isso utilizando o SQL Server e ver como é possível transformar linhas em colunas com o SQL.
Para acompanhar este artigo, vamos primeiro criar uma tabela de testes e depois inserir as informações que serão utilizadas.
CREATE TABLE minha_tabela(
[id] [int] IDENTITY(1,1) NOT NULL,
[data] [date] NULL,
[departamento] [varchar](50) NULL,
[tipo_despesa] [varchar](50) NULL,
[valor] [numeric](18, 2) NULL,
CONSTRAINT [PK_minha_tabela] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
Depois de criada a tabela, vamos adicionar alguns registros.
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-01-04\', \'COMPRAS\', \'CADEIRA\', 200);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-01-06\', \'MKT\', \'VENTILADOR\', 100);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-01-08\', \'EXPEDICAO\', \'MATERIAL ESCRITORIO\', 300);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-01-10\', \'TI\', \'COMPUTADOR\', 1200);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-01-15\', \'COMPRAS\', \'MESA\', 300);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-01-17\', \'MKT\', \'CORTINA\', 100);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-01-18\', \'MKT\', \'TAPETE\', 100);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-01-18\', \'EXPEDICAO\', \'TELEFONE\', 80);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-01-21\', \'TI\', \'CABO DE REDE\', 300);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-02-01\', \'COMPRAS\', \'IMPRESSORA\', 500);
INSERT INTO minha_tabela (data, departamento, tipo_despesa, valor) VALUES (\'2017-02-01\', \'MKT\', \'TV\', 1200);
Após carregar os dados acima, a sua tabela deve ter o seguinte conteúdo:
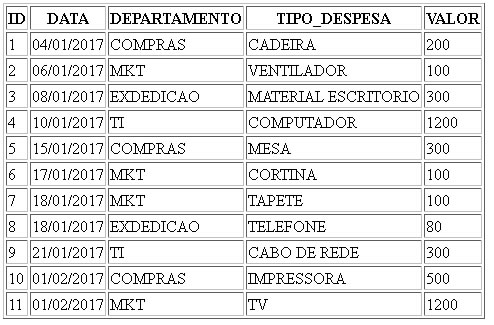
Nosso objetivo é fazer a seguinte análise, criar uma coluna para cada departamento, de modo a mostrar o total gasto no mês de janeiro. O resultado final será transformar linhas em colunas.
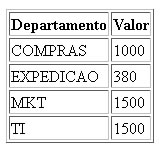
Se fizermos um agrupamento por departamento, ordenando por nome do departamento
SELECT departamento, sum(valor) as valor from minha_tabela group by departamento order by departamento
Vamos ter o seguinte resultado:
Para poder inverter esse tipo de análise, o SQL SERVER disponibiliza o comando PIVOT. O PIVOT trabalha da seguinte forma:
SELECT (colunas que eu quero utilizar da consulta de referência)
FROM
(consulta de referência que vai trazer os dados desejados) alias_desta_consulta
PIVOT (Função de Agrupamento e nome das colunas que serão criadas pelo agrupamento)
Apesar da sintaxe parecer complexa num primeiro momento, na prática a consulta não tem segredos. Veja como fica a solução do exemplo proposto:
select * from (
select DEPARTAMENTO, VALOR
FROM minha_tabela
where month(data) = 1 and year(data) = 2017
) DataTable
PIVOT
(
SUM(VALOR)
FOR DEPARTAMENTO
IN ([COMPRAS], [MKT])
) PivotTable
No exemplo acima, fazemos uma consulta onde desejamos trabalhar com as colunas departamento e valor que atendam a condição de ser do mês de janeiro. Essa consulta é registrada com o alias "Datatable". Sobre este resultado, aplicamos uma função de agrupamento para a coluna "valor", a função escolhida foi a SUM, desta forma somamos todos os valores. O resultado da soma vai ser quebrado em novas colunas, o campo que vai servir de base será o campo departamento.
Na tabela que mostra os dados que estamos trabalhos podemos ver que existem quatro departamentos. Vamos criar apenas duas colunas, uma para o departamento Compras, e outra para o departamento MKT.
O retorno deste PIVOT seria o seguinte:

Se você quiser saber a quantidade de compras ao invés do valor, basta fazer o seguinte ajuste:
select * from (
select DEPARTAMENTO, VALOR
FROM minha_tabela
where month(data) = 1 and year(data) = 2017
) DataTable
PIVOT
(
COUNT (VALOR)
FOR DEPARTAMENTO
IN ([COMPRAS], [MKT])
) PivotTable
E o resultado seria:

Se você trabalha com o banco de dados MySQL e deseja obter o mesmo resultado, veja o link a seguir:
Convertendo linhas em colunas usando MySQL
Encerramento
Neste artigo você viu como é possível transformar linhas de resultados em colunas com o SQL Server.
Uma outro recurso muito comum é converter varias linhas de resultados em uma única coluna. Isso é utilizado quando queremos por exemplo agrupar categorias e exibir numa única coluna as subcategorias relacionadas
Se você quer aprender como fazer isso, não deixe de conferir o link a seguir:






